Why the hell do we need Avro schemas?
Before we start to talk about the awesomeness of using Avro in your future application let's first look into why we need schemas in Kafka and what problems it solves.
One of the major issues is that Kafka takes in bytes as input and publishes them, in this Kafka has no clue of what the data is and does not perform any kind of data verification to it.
So from a Kafka perspective, a producer sends in bytes of information, it does not know if the data is a string or boolean and quite frankly it doesn't care! and these bytes of unvalidated chaos are consumed by the consumer services.

So if Kafka doesn't care, What if a producer sends in bad data, and what if a field is renamed or the data format for a field changes, in that case, the consumer might break when trying to read in data. The solution for this problem is to have a structure that is self describable and we need to be able to change data without breaking down consumers.
Enter Avro Schema
Avro schema provides us with the solution that we were talking about. Essentially Avro schemas are files that a written in JSON to describe data and provide structure to the data that’s being consumed and produced. Let’s take a look at a simple Avro schema example.

This is probably one of the simplest schemas you might see but this will make do for now. People who have been working with JSON for a while will look a lot familiar. The name property that we provide is for the name of the schema and in our case the value is FullName. The most important part of this schema is the fields property where we would specify all the property the producer would send along with their data types and documentation for the property (Avro’s way of being descriptive).
How to implement this awesomeness in an exiting Kafka application?
There are multiple ways we can implement Avro schema into an application but we are going to look into a method called Specific Record.
Before we go any further and if in the case you happen to love coding along to tutorials, make sure that you include the following dependency.
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.8.2</version>
</dependency><dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>3.3.1</version>
</dependency>
Now, we’ll look into how we can create an Avro object from a schema file to enforce type. The code for the Avro object is generated from the schema file. In our case, we’ll make use of the Avro Maven plugin to generate objects. So to add in the maven plugin we have to again add the following code to pom.xml
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>${avro.version}</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/resources/avro</sourceDirectory>
<stringType>String</stringType>
<createSetters>false</createSetters>
<enableDecimalLogicalType>true</enableDecimalLogicalType>
<fieldVisibility>private</fieldVisibility>
</configuration>
</execution>
</executions>
</plugin>If we look closely into the plugin configuration, we can see sourceDirectory where we would specify the directory to look for the Avro schema files, which will create soon.

Onward with creating a schema
To create a schema, go into the resources directory, create a new folder called avro and create a file named sample-schema.avsc.
Just for the sake of this post, the schema will have some basic properties like, first-name and last-name. Make sure that you provide the correct package in the namespace property for the schema. The entire schema file will look like.
{
"type": "record",
"namespace": "com.example.sample",
"name": "SampleSchema",
"version": "1",
"fields": [
{
"name": "firstName",
"type": "string"
},
{
"name": "lastName",
"type": "string"
}
]
}To generate the Avro object, open up the terminal in your project directory and execute the following command.
mvn clean
mvn packageThe maven clean command clears the target directory into which Maven normally builds your project. The maven package command builds the project and packages the resulting JAR file into the target directory and also generates the Avro object for the schema we just created inside the generated-sources directory. In our case, the generated Avro object will have the class name as SampleSchema.java since that’s the name of the schema that we’ve provided in the schema file.
To use the created Avro object, make sure that you configure the Kafka template to take in the message as SampleSchema type.
@Bean
public KafkaTemplate<String, SampleSchema> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}Then use the kafkaTemplate.send() method to send data to a specific topic in the newly created schema type.
Where does Schema Registry come into the picture?

So we saw about Avro schema and how we can create them. Schema registry essentially provides us with a way to store and retrieve them.
Some of you might have this question, Why the hell do we need a separate component for Schema Registry? Why not have the Kafka broker verify the messages they receive? because the answer is adding this functionality to the Kafka broker will break what makes Kafka broker awesome in the first place, brokers do not parse or even read data and in return do not consumer CPU resources. It also performs zero-copy meaning that it takes the input without even loading them into memory. Hence for all these reasons, we have the registry as a separate component.
What happens when we add Schema Registry?
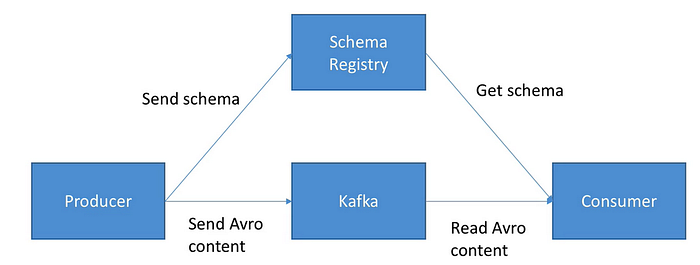
Up until now, The producer will send both the schema and the message content to Kafka and the consumer will read both the schema and content from Kafka. After introducing the schema registry, The producer will send Avro schema to the Schema Registry and the consumer will read the schema from the schema registry instead of reading the schema from Kafka. This will also reduce the size of the message being sent to Kafka.
After starting the Schema Registry service, to configure the producer/consumer to make use of it, add-in the schema registry URL configuration as
configProps.put("schema.registry.url", "http://127.0.0.1:8081");Schema Registry: Deep Dive
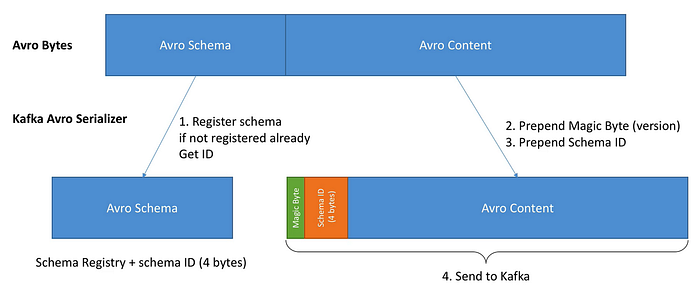
One of the ways in which the size of the data being sent to Kafka is reduced is when the producer first tries to send an event it sends the schema for it to Schema Registry and the schema registry then returns a four-byte schema id. The producer then sends the data along with the schema ID to Kafka. The consumer then extracts the schema ID and gets the respective schema from the registry and performs validation. In this way, the overall content size of the data is reduced considerably.
